How to setup Hadoop for single node cluster in CentOS
To setup Hadoop for single node cluster in CentOS
Hadoop is an open source software to process big data. If the data size is beyond the limit of hardware capability, it stores and process the data in a distributed manner across all the datanodes in the cluster. The datas are stored in the Hadoop Distributed File System (HDFS).
To install Java
Hadoop requires java. Go to /opt/ directory and download the java package and extract it. Visit the following link to download java.
http://download.oracle.com/otn-pub/java/jdk/8u91-b14/jdk-8u91-linux-x64.tar.gz
[root@linuxhelp ~]# cd /opt/
[root@linuxhelp ~]# wget --no-cookies --no-check-certificate --header " Cookie: gpw_e24=http%3A%2F%2Fwww.oracle.com%2F oraclelicense=accept-securebackup-cookie" http://download.oracle.com/otn-pub/java/jdk/8u91-b14/jdk-8u91-linux-x64.tar.gz
[root@linuxhelp opt]# tar -xzf jdk-8u91-linux-x64.tar.gz
[root@linuxhelp opt]# ls
jdk1.8.0_91 jdk-8u91-linux-x64.tar.gz rh
After extracting use alternatives command to install java.
[root@linuxhelp opt]# cd jdk1.8.0_91/
[root@linuxhelp jdk1.8.0_91]# alternatives --install /usr/bin/java java /opt/jdk1.8.0_91/bin/java 2
[root@linuxhelp jdk1.8.0_91]# alternatives --config java
There are 5 programs which provide ' java' .
Selection Command
-----------------------------------------------
*+ 1 /usr/lib/jvm/jre-1.7.0-openjdk.x86_64/bin/java
2 /usr/lib/jvm/jre-1.5.0-gcj/bin/java
3 /usr/lib/jvm/jre-1.8.0-openjdk.x86_64/bin/java
4 /usr/lib/jvm/jre-1.6.0-openjdk.x86_64/bin/java
5 /opt/jdk1.8.0_91/bin/java
Enter to keep the current selection[+], or type selection number: 5
Setup jar and javac commands path using alternatives.
[root@linuxhelp jdk1.8.0_91]# alternatives --install /usr/bin/jar jar /opt/jdk1.8.0_91/bin/jar 2
[root@linuxhelp jdk1.8.0_91]# alternatives --install /usr/bin/javac javac /opt/jdk1.8.0_91/bin/javac 2
[root@linuxhelp jdk1.8.0_91]# alternatives --set jar /opt/jdk1.8.0_91/bin/jar
[root@linuxhelp jdk1.8.0_91]# alternatives --set javac /opt/jdk1.8.0_91/bin/javac
After java installation, check the java version.
[root@linuxhelp jdk1.8.0_91]# java -version
java version " 1.8.0_91"
Java(TM) SE Runtime Environment (build 1.8.0_91-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.91-b14, mixed mode)
Next we need to configure the environment variables as follows.
[root@linuxhelp jdk1.8.0_91]# export JAVA_HOME=/opt/jdk1.8.0_91/
[root@linuxhelp jdk1.8.0_91]# export JRE_HOME=/opt/jdk1.8.0_91/jre
[root@linuxhelp jdk1.8.0_91]# export PATH=$PATH:/opt/jdk1.8.0_91/bin:/opt/jdk1.8.0_91/jre/bin/
To install Hadoop
Create a user for hadoop as follows.
[root@linuxhelp ~]# useradd hadoop
[root@linuxhelp ~]# passwd hadoop
Changing password for user hadoop.
New password:
Retype new password:
passwd: all authentication tokens updated successfully.
After creating a user account for hadoop, switch to hadoop user account and generate the ssh key file as follows.
We need to install hadoop from the hadoop user account only. All the configuration shown below made only in hadoop user account.
[root@linuxhelp ~]# su - hadoop [hadoop@linuxhelp ~]$ ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): Created directory ' /home/hadoop/.ssh' . Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/hadoop/.ssh/id_rsa. Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub. The key fingerprint is: 9e:a1:31:11:21:70:32:d3:ba:52:44:f1:76:b8:b6:c4 hadoop@linuxhelp.com The key' s randomart image is: +--[ RSA 2048]----+ | .B+o o. | | .*.o . | | . .+ o | | oo o . | | . .E o S | |. .o . = o | | . . . o | | | | | +-----------------+ [hadoop@linuxhelp ~]$ cat ~/.ssh/id_rsa.pub > > ~/.ssh/authorized_keys [hadoop@linuxhelp ~]$ chmod 0600 ~/.ssh/authorized_keys
Navigate to the link to download hadoop. Choose the version accordingly.,
http://apache.claz.org/hadoop/common/
[hadoop@linuxhelp ~]$ cd [hadoop@linuxhelp ~]$ pwd /home/hadoop [hadoop@linuxhelp ~]$ wget http://apache.claz.org/hadoop/common/hadoop-2.7.2/hadoop-2.7.2.tar.gz [hadoop@linuxhelp ~]$ tar -xzf hadoop-2.7.2.tar.gz [hadoop@linuxhelp ~]$ ls hadoop-2.7.2 hadoop-2.7.2.tar.gz [hadoop@linuxhelp ~]$ mv hadoop-2.7.2 hadoop [hadoop@linuxhelp ~]$ ls hadoop hadoop-2.7.2.tar.gz
Edit the .bashrc file as follows, which is located in/home/hadoop directory.
In your root directory also .bashrc file is available. Do not edit this file.
[hadoop@linuxhelp ~]$ vim .bashrc
export HADOOP_HOME=/home/hadoop/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
Run the following command to apply the changes.
[hadoop@linuxhelp ~]$ source ~/.bashrc
Edit the /home/hadoop/etc/hadoop-env.sh file and add the below mentioned line to export JAVA_HOME
[hadoop@linuxhelp ~]$ cd hadoop/etc/hadoop/ [hadoop@linuxhelp hadoop]$ ls capacity-scheduler.xml hadoop-env.sh httpfs-env.sh kms-env.sh mapred-env.sh ssl-server.xml.example configuration.xsl hadoop-metrics2.properties httpfs-log4j.properties kms-log4j.properties mapred-queues.xml.template yarn-env.cmd container-executor.cfg hadoop-metrics.properties httpfs-signature.secret kms-site.xml mapred-site.xml.template yarn-env.sh core-site.xml hadoop-policy.xml httpfs-site.xml log4j.properties slaves yarn-site.xml hadoop-env.cmd hdfs-site.xml kms-acls.xml mapred-env.cmd ssl-client.xml.example [hadoop@linuxhelp hadoop]$ vim hadoop-env.sh
Comment the following line.
export JAVA_HOME=${JAVA_-HOME}
And add the following line into it.
export JAVA_HOME=/opt/jdk1.7.0_91/
Now start editing the configuration file for hadoop for single node cluster in the same directory.
[hadoop@linuxhelp hadoop]$ vim core-site.xml
Add the following entries into it.
fs.default.name hdfs://localhost:9000
[hadoop@linuxhelp hadoop]$ vim hdfs-site.xml
Add the following entries into it.
dfs.replication 1 dfs.name.dir file:///home/hadoop/hadoopdata/hdfs/namenode dfs.data.dir file:///home/hadoop/hadoopdata/hdfs/datanode
[hadoop@linuxhelp hadoop]$ cp mapred-site.xml.template mapred-site.xml
[hadoop@linuxhelp hadoop]$ vim mapred-site.xml
Add the following entries into it.
mapreduce.framework.name yarn
[hadoop@linuxhelp hadoop]$ vim yarn-site.xml
Add the following entries into it.
yarn.nodemanager.aux-services mapreduce_shuffle
Now format the namenode by using following command.
[hadoop@linuxhelp hadoop]$ hdfs namenode -format
16/06/21 15:32:13 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = linuxhelp.com/192.168.5.103
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.7.2
STARTUP_MSG: classpath = /home/hadoop/hadoop/etc/hadoop:/home/hadoop/hadoop/share/hadoop/common/lib/curator-client-2.7.1.jar:/home/hadoop/hadoop/share/hadoop/common/lib/asm-3.2.jar:/home/hadoop/hadoop/share/hadoop/common/lib/commons-digester-
.
.
.
16/06/21 15:32:16 INFO namenode.FSImage: Allocated new BlockPoolId: BP-2052947587-192.168.5.103-1466503336749
16/06/21 15:32:17 INFO common.Storage: Storage directory /home/hadoop/hadoopdata/hdfs/namenode has been successfully formatted.
16/06/21 15:32:17 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid > = 0
16/06/21 15:32:17 INFO util.ExitUtil: Exiting with status 0
16/06/21 15:32:17 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at linuxhelp.com/192.168.5.103
************************************************************/
Start the service by executing the start-dfs.sh and start-yarn.sh script files located in the directory /home/hadoop/hadoop/sbin as follows.
[hadoop@linuxhelp hadoop]$ cd /home/hadoop/hadoop/sbin/ [hadoop@linuxhelp sbin]$ start-dfs.sh 16/06/21 15:35:21 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Starting namenodes on [localhost] The authenticity of host ' localhost (::1)' can' t be established. RSA key fingerprint is e4:e3:9b:a5:f3:b9:4a:01:a7:93:30:6e:fd:8f:f9:95. Are you sure you want to continue connecting (yes/no)? yes . . . Enter passphrase for key ' /home/hadoop/.ssh/id_rsa' : 0.0.0.0: starting secondarynamenode, logging to /home/hadoop/hadoop/logs/hadoop-hadoop-secondarynamenode-linuxhelp.com.out 16/06/21 15:36:44 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable [hadoop@linuxhelp sbin]$ start-yarn.sh starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop/logs/yarn-hadoop-resourcemanager-linuxhelp.com.out Enter passphrase for key ' /home/hadoop/.ssh/id_rsa' : localhost: starting nodemanager, logging to /home/hadoop/hadoop/logs/yarn-hadoop-nodemanager-linuxhelp.com.out
To check started service using “ jps” command
Now exit form hadoop user account and switch to root account. Run the below command to install jps command for java.
[root@linuxhelp ~]# update-alternatives --install /usr/bin/jps jps /opt/jdk1.8.0_91/jps 1
Run the jps command to verify the started services.
[root@linuxhelp ~]# jps
13376 NameNode
14184 NodeManager
13707 SecondaryNameNode
13515 DataNode
14495 Jps
13887 ResourceManager
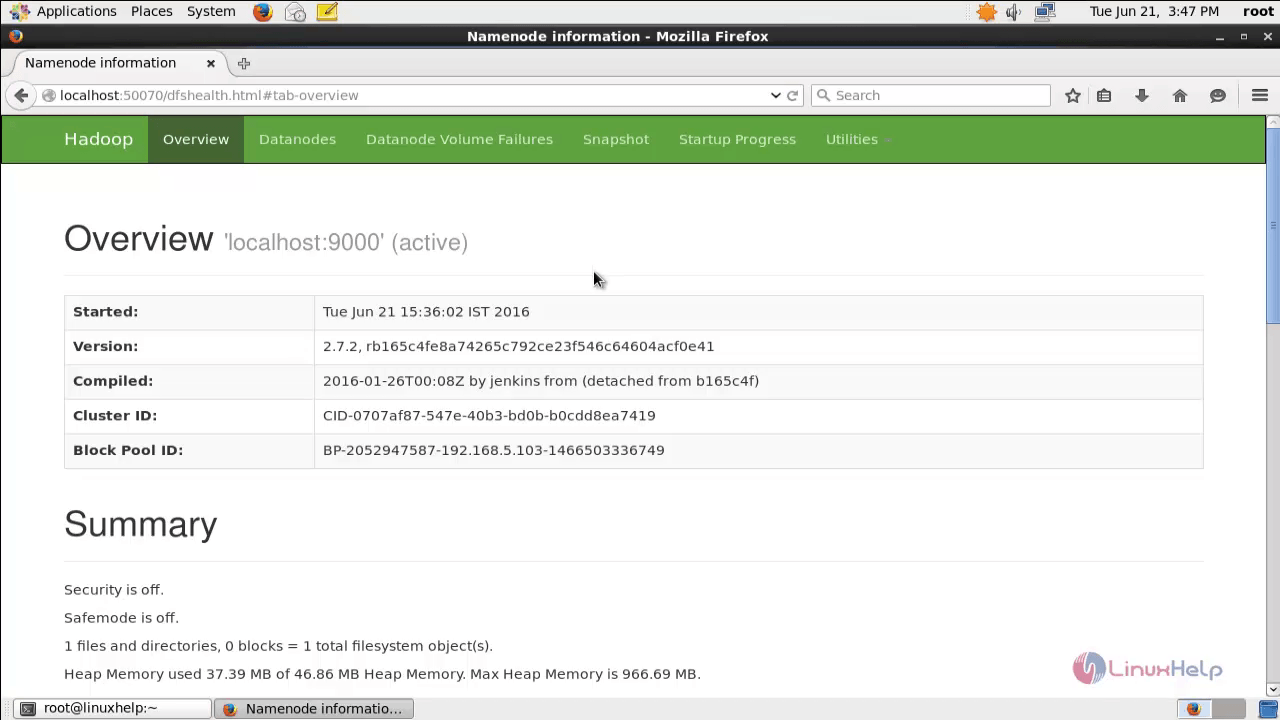
Now hadoop is configured and services are running. Open your browser and type http://localhost:50070
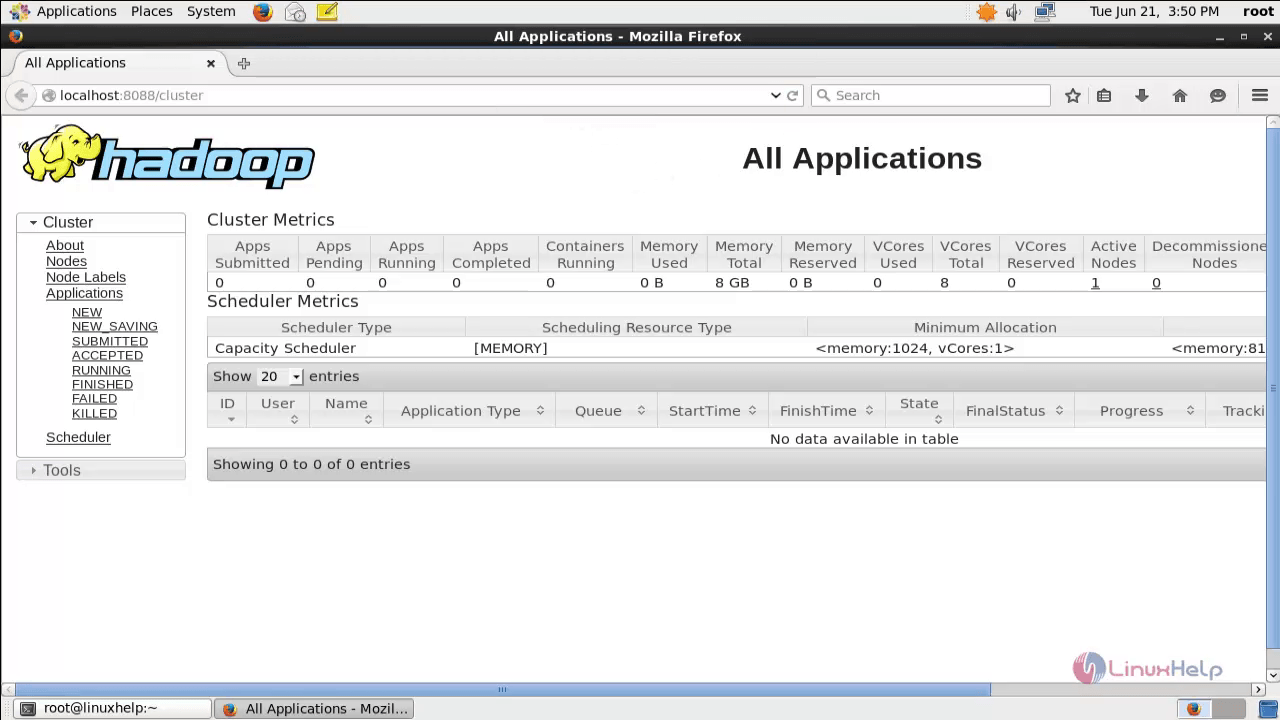
Enter http://localhost:8088 for cluster information in the browser.
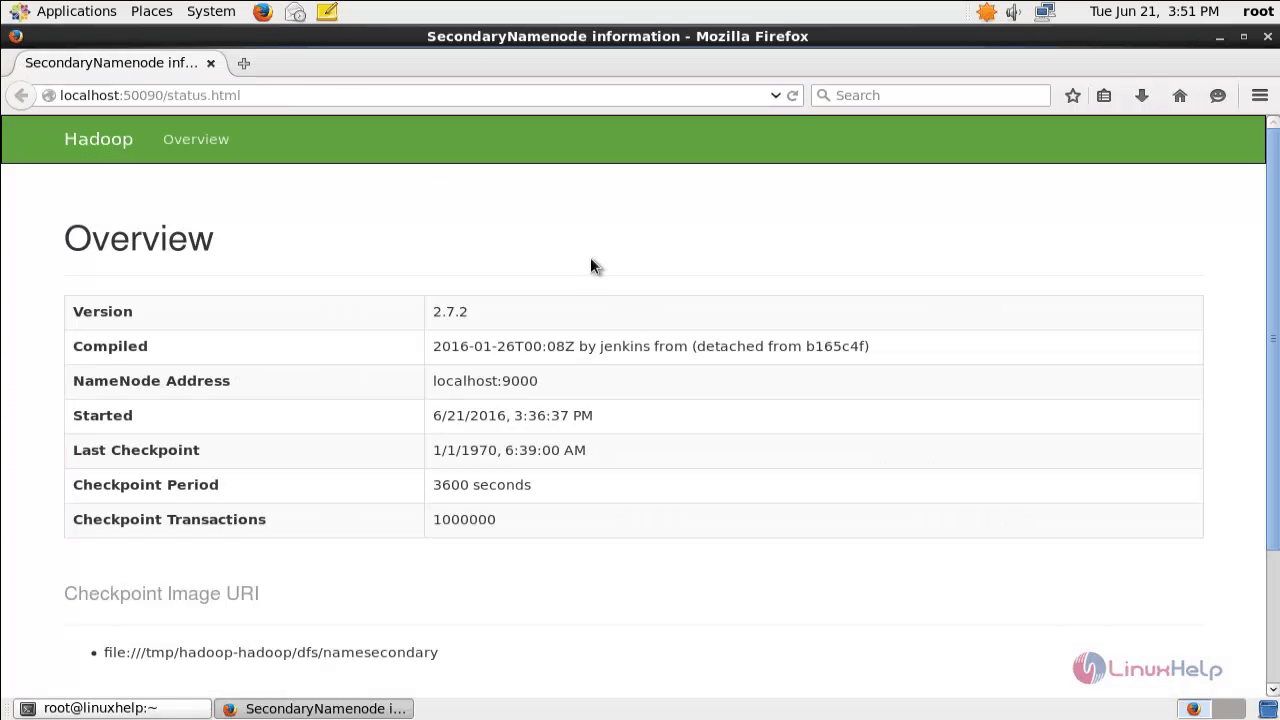
Type http://localhost:50090 for Secondary Namenode information.
Comments ( 1 )